Reference Library
Vol. 1·Saturday, May 9, 2026
How Voice AI Actually Works: The Three Architectures Reshaping the Way We Talk to Machines
Noah Ogbi13 min read
Tips, corrections, or questions? support@omniscient.media
TopicsResearch
Tips, corrections, or questions? support@omniscient.media
Consequential AI, explained and evaluated, every weekday.
The Omniscient Bulletin: 5 to 7 items a day with the take, not the recap.
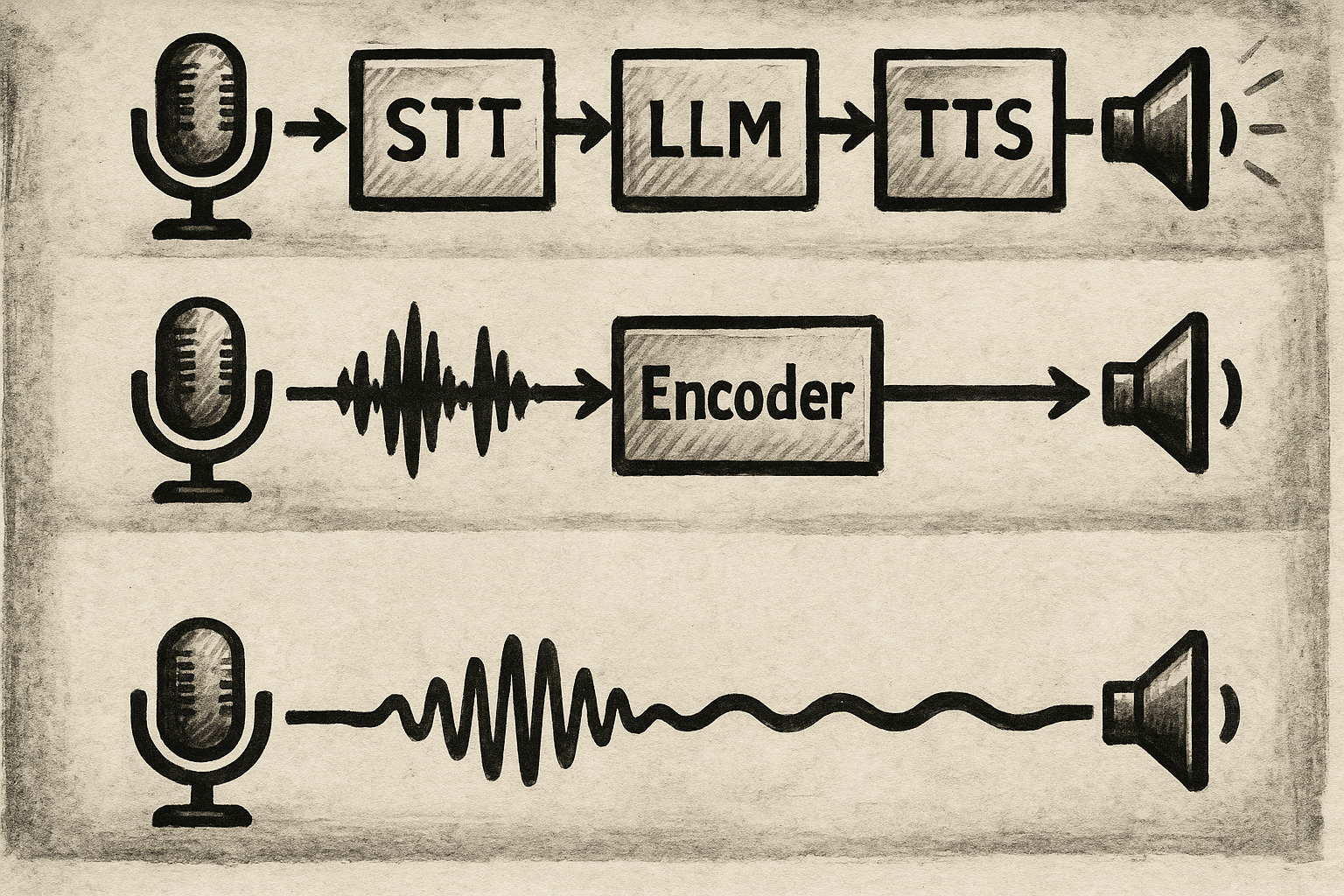
A voice AI pipeline is the sequence of processing steps that turns a person's spoken words into an intelligent spoken response. Until recently, that sequence followed a single, universal template: convert speech to text, feed text to a language model, convert the reply back to audio. The appeal was pragmatic - teams could assemble the best available component in each category, swap parts independently, and keep each stage auditable. The cost was structural: three sequential handoffs, each introducing latency, each discarding something the previous stage had captured.
That architecture is now giving way to something different. Three distinct structural approaches have emerged in 2026, each making a different bet on where understanding should happen, which information to preserve, and how to cut the time between when a person stops speaking and when the agent starts responding. The choice between them has real consequences: for latency, for naturalness, for cost, and for the kinds of tasks a voice agent can reliably handle in production.
OpenAI's May 7 announcement of GPT-Realtime-2 - the first voice model built on GPT-5-class reasoning - is a useful occasion to map the landscape.[1] The model is genuinely notable, but the more durable story is architectural: what the three approaches are, what they sacrifice to gain their advantages, and where each one fits.
The chained pipeline - sometimes called the cascaded STT-LLM-TTS architecture - processes voice in a strict linear sequence: speech-to-text, language model, text-to-speech, in that order.[2] Its appeal was modularity. Each component could be swapped, benchmarked, and improved in isolation. A team could replace its transcription engine without touching the language model, or upgrade its TTS voice without retraining anything upstream. Debugging was comparatively straightforward: if something went wrong, you knew which stage to look at.
The pipeline's structural problem is sequential latency. Every handoff costs time. The STT model must finish transcribing before the LLM can begin reasoning; the LLM must generate its first tokens before TTS can begin synthesizing. In practice, this adds several hundred milliseconds at minimum, and often far more in network-bound cloud deployments. Human conversational response times average around 200 milliseconds;[2] even a well-optimized cascade pipeline rarely gets close.
There is a second, subtler cost: information loss at the transcription boundary. When audio becomes text, everything that was not semantic content disappears. Tone, hesitation, emotional coloring, the rising inflection that signals a question - none of it survives in a plain transcript. A language model reasoning over text has no way to recover what was stripped at that boundary. The system processes what people said, but not how they said it.
For many use cases, these tradeoffs are entirely acceptable. Chained pipelines remain cheaper to build, easier to audit, and more flexible when specific components need to be customized. A customer support deployment that needs a specific accent for TTS, a custom domain-tuned STT engine, and a fine-tuned LLM is often better served by a modular cascade than by any of the tightly coupled alternatives. Example implementations include Deepgram or Gladia for transcription, GPT-5.4 or Gemini 3 Flash for language reasoning, and ElevenLabs or Cartesia for synthesis.[2]
The half-cascade architecture makes one targeted structural change to the classic pipeline: it removes the transcription step at the front. Rather than converting speech to text before anything else happens, an audio encoder processes the incoming sound directly, producing vector representations that carry not just the words but the acoustic texture around them - the hesitation before a correction, the flattened affect of a tired caller, the pace that signals urgency. Those representations feed into a text-native language model, keeping the reasoning layer essentially unchanged while enriching what it receives.[2]
This is the approach used by OpenAI's Realtime API, Google's Gemini 3.1 Flash Live, and xAI's Grok Voice Agent API. It is the dominant architecture in production voice AI today, and the right way to understand what "speech-to-speech" usually means in commercial contexts: not a single unified model, but a tighter coupling of audio understanding and language reasoning, with text-based reasoning still at the core.
The gains over the chained pipeline are tangible. Because the audio encoder and language model can operate concurrently with the incoming audio stream rather than waiting for a finalized transcript, latency drops measurably. The chart below shows time-to-first-audio across the leading production systems as of early May 2026, measured by Artificial Analysis:[3]

The wide range within the half-cascade category - xAI at 0.78 s versus Gemini Flash Live at 2.98 s - illustrates how much implementation quality matters even when two systems share the same architectural approach.
GPT-Realtime-2 is the most capable half-cascade model currently available, introducing several features that address the limitations developers encountered in production deployments. The context window expands from 32K to 128K tokens, enabling longer coherent sessions and more complex agentic workflows.[1] Reasoning effort is now configurable across five levels - minimal, low, medium, high, and xhigh - allowing developers to trade latency against deliberation depending on the task.[1] Parallel tool calls let the model run multiple integrations simultaneously while narrating its actions aloud, keeping conversations fluid during multi-step tasks.[1]
On benchmark evaluations tied closely to production voice use cases, the improvements are measurable. GPT-Realtime-2 at high reasoning effort scores 15.2% higher on Big Bench Audio than its predecessor gpt-realtime-1.5; at xhigh reasoning effort, it scores 13.8% higher on Audio MultiChallenge, which tests multi-turn conversational intelligence including instruction following, context integration, and handling natural speech corrections.[1] Zillow, an early tester, reported a 26-point lift in call success rate on its hardest adversarial internal benchmark, reaching 95% from 69%, after prompt optimization with the new model.[1]
The half-cascade's remaining limitation is structural rather than a matter of tuning. The reasoning layer is still text-native: audio comes in, gets encoded, and the language model operates in token space. This means TTS output - however good - is generated from a representation that has already been abstracted away from the original audio. True emotional continuity from input to output requires a different approach entirely.
Native audio models are defined by what they eliminate: there is no transcription step, no intermediate text representation, and no synthesis stage running separately from the model that produces the reply. A single neural network receives audio, reasons internally in a latent space where linguistic meaning and acoustic character coexist, and generates audio output directly. The text layer - the main inspection point and the main reasoning anchor in the other two architectures - is absent throughout.[2]
The theoretical appeal is significant. A model that reasons in audio space can, in principle, preserve the full signal from input to output: the hesitation in someone's voice, the urgency beneath a question, the emotional register of a difficult conversation. It can also support full-duplex interaction - responding while the user is still speaking, handling natural overlaps and interruptions the way human conversations actually work.
Two production-ready native audio models stand out in 2026. Amazon Nova 2 Sonic, generally available on AWS Bedrock since December 2025, scores approximately 88% on Big Bench Audio with a time-to-first-audio of 1.14 seconds.[3] Its pricing - $3 per million audio input tokens and $12 per million audio output tokens, roughly $0.02 per minute in typical turn structures - sits an order of magnitude below OpenAI Realtime, which charges $32 per million input tokens and $64 per million output tokens.[1][3]
The open-source frontier is led by Step-Audio R1.1 (Realtime), released by StepFun in January 2026 under the Apache 2.0 license. Its Dual-Brain Architecture splits reasoning and articulation into separate components within a single native audio system, enabling complex reasoning while maintaining fluent real-time speech. It currently tops the Big Bench Audio leaderboard at 97.6% accuracy, outperforming every commercial alternative on that benchmark.[3][4] Moshi, from French research lab Kyutai, takes a different approach: a fully integrated audio-to-audio model with model-level latency around 160 milliseconds and natural full-duplex support, available as open weights for self-hosting.[5]
The honest accounting of native audio's tradeoffs: these models are harder to train, harder to debug, and harder to customize. There is no text layer to inspect when something goes wrong. Voice customization - swapping in a specific accent, enforcing a particular persona - is less straightforward than in a cascade system where TTS is a replaceable component. The field is moving fast enough that these limitations are narrowing, but they remain real constraints for production deployments that need predictability and control.
The table below summarizes the key dimensions across all three approaches and the leading production systems in each category as of May 2026.
Dimension | Chained Pipeline | Half-Cascade | Native Audio |
|---|---|---|---|
How it works | STT → LLM → TTS in strict sequence | Audio encoder → text-native LLM → TTS | Single model: audio in, audio out |
Latency | Highest (sequential handoffs) | Lower (concurrent streaming) | Varies; fastest models approach 0.78 s |
Audio nuance preserved | Lost at STT boundary | Partially retained via audio encoder | Fully preserved end-to-end |
Flexibility | Highest - components are swappable | Medium - encoder-LLM tightly coupled | Lowest - monolithic architecture |
Debuggability | Easy - text layer is inspectable | Moderate - text reasoning is visible | Hard - no intermediate text layer |
Leading systems | Deepgram + GPT-5.4 + Cartesia | GPT-Realtime-2, Gemini 3.1 Flash Live, Grok Voice Agent | Amazon Nova 2 Sonic, Step-Audio R1.1, Moshi |
Best fit | Cost-sensitive, custom component requirements | Production agentic voice; premium support | Maximum naturalness; full-duplex interactions |
GPT-Realtime-2 is important not because it changes the architecture - it is still a half-cascade system - but because it raises the intelligence ceiling of what that architecture can do. The shift from 32K to 128K context is a meaningful unlock for agentic voice applications that need to sustain coherent multi-turn sessions over the course of a complex workflow. Configurable reasoning effort means developers can now tune the latency-intelligence tradeoff per application, rather than accepting a single fixed operating point.
OpenAI simultaneously released two companion models alongside GPT-Realtime-2. GPT-Realtime-Translate handles live speech translation across 70-plus input languages into 13 output languages, priced at $0.034 per minute. GPT-Realtime-Whisper delivers streaming transcription at $0.017 per minute, enabling the kind of live captions and real-time meeting notes that have historically required a separate transcription stack.[1] Together, the three models represent a more complete voice infrastructure offering - reasoning, translation, and transcription - rather than a single model upgrade.
The pricing context matters. At $32/$64 per million tokens for GPT-Realtime-2, OpenAI sits at a significant premium relative to Amazon Nova 2 Sonic (approximately one-tenth the cost per minute) and Google Gemini 3.1 Flash Live (approximately one-third).[3] For applications where reasoning quality and instruction following at GPT-5-class are genuinely differentiating - complex agentic workflows, compliance-sensitive deployments like Zillow's Fair Housing guardrails - that premium may be straightforward to justify. For high-volume, latency-tolerant applications where audio naturalness matters more than reasoning sophistication, native audio alternatives are now compelling on both quality and cost.
The most interesting open question in voice AI architecture is whether native audio models can close the reasoning gap. Step-Audio R1.1's 97.6% Big Bench Audio score already surpasses every half-cascade system on that benchmark, but benchmark performance on audio reasoning does not automatically translate to the kind of structured tool-calling and multi-step task execution that production voice agents require. The text-native reasoning layer in half-cascade systems provides a reliable scaffolding for those capabilities that native audio models are still developing.
A second question is whether the category distinctions themselves will hold. Google's Gemini 3.1 Flash Live was described at launch as a "unified audio-to-audio model" that consolidated what had been separate half-cascade and native-audio preview paths - suggesting that the cleanest architectural divisions may blur as multimodal training improves.[2] The end state, in the medium term, is likely a spectrum rather than three discrete categories: systems that vary continuously in how much audio-space reasoning they perform, tuned for different operating points on the latency-naturalness-cost surface.
For now, the practical guide is straightforward: if you need maximum control and customizability, build a cascade pipeline. If you need production-grade agentic voice with strong reasoning and tool use, the half-cascade systems - led by GPT-Realtime-2 for intelligence-critical applications - are the mature choice. If you are optimizing for naturalness, emotional continuity, and cost at scale, native audio is ready for serious consideration.
OpenAI - Advancing voice intelligence with new models in the API (May 7, 2026) Inline ↗
Softcery - Real-Time (S2S) vs Cascading (STT/TTS) Voice Agent Architecture (April 24, 2026) Inline ↗
Artificial Analysis - Speech to Speech AI Model and Provider Leaderboard Inline ↗
Kyutai - Moshi, GitHub (theoretical latency 160 ms; practical ~200 ms on L4 GPU) Inline ↗