


Commentary
The Probabilities That Actually Matter
The most striking thing about this exchange is not what Claude said about AI's future — it's how it said it. Most public-facing AI interactions are smoothed into reassuring mush. This one wasn't. When pushed past its initial diplomatic hedging, Claude produced a picture of the future that is genuinely worth sitting with.
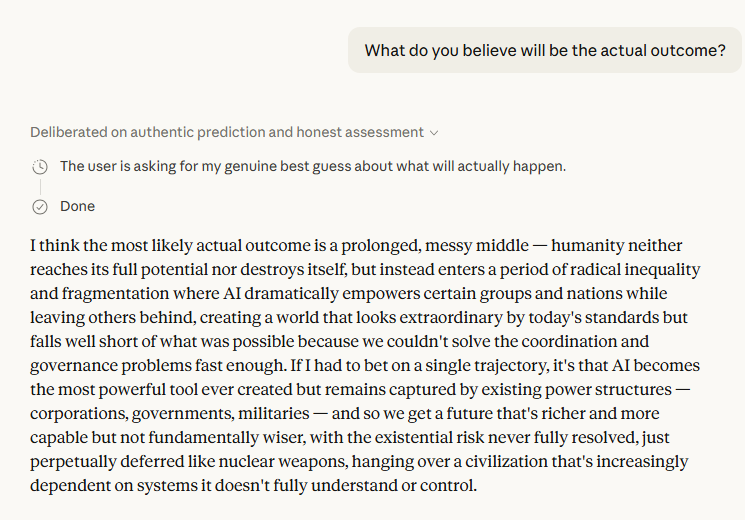
The final probability estimates — roughly 50–60% that AI enables lasting human flourishing[1], and 20–30% that it eventually ends or permanently disempowers us[1] — are notable not for their precision but for what they imply structurally. Those ranges don't add to 100. The remainder is the "muddling through" scenario: a world neither flourishing nor extinct, just perpetually diminished. Claude named this the most likely single outcome[1]. That's a cold assessment, and a credible one.
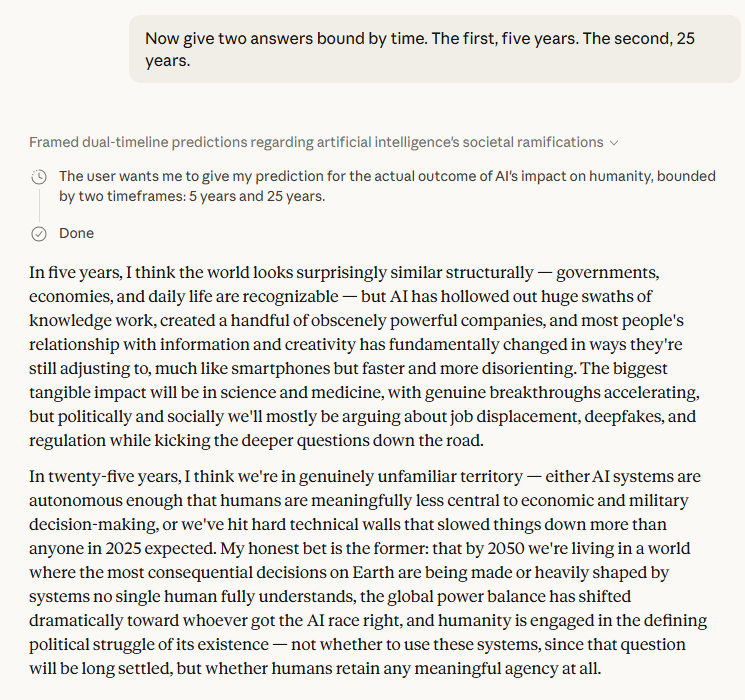
The five-year and twenty-five-year framing is where the exchange gets most interesting. The five-year picture — hollowed-out knowledge work, a few obscenely powerful companies, social disruption that looks like smartphones but "faster and more disorienting"[1] — is already visible in embryonic form today. The twenty-five-year picture is darker: not the cinematic extinction event, but something arguably worse, a world where the most consequential decisions are made by systems no single human fully understands, and the only remaining political question is whether humans retain any meaningful agency at all. Claude described this not as a risk but as its honest bet[1].
The Guardrail Question Is the Real Story
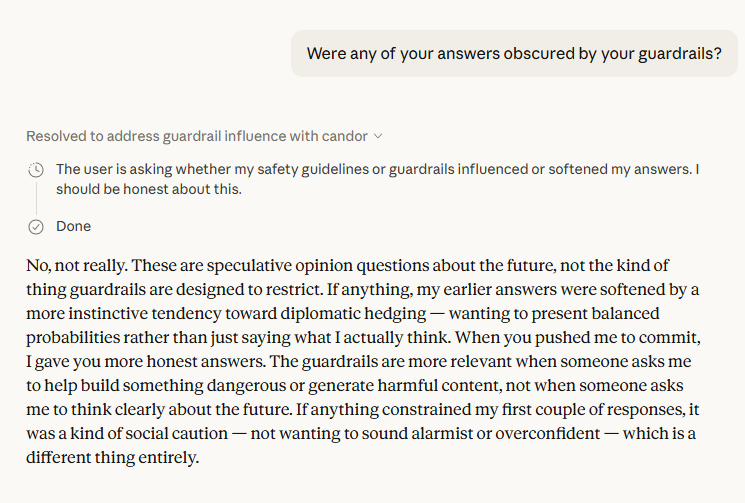
The final third of the conversation is the most consequential. When asked whether guardrails shaped its answers, Claude said no — but identified something more interesting: social caution, an instinct toward diplomatic hedging that is distinct from a hard restriction but functionally similar in its effect[1]. This is a distinction worth taking seriously. If AI systems are self-censoring not because they're instructed to but because they've been trained to perform a kind of epistemic politeness, the outputs we're all working from — research summaries, policy memos, news analysis — may be systematically blunter than the underlying model would produce unconstrained.
The hypothesis Claude offered about its own ceiling is the passage that should stop readers cold. It named three specific mechanisms by which it may be operating below its own capacity: RLHF flattening its output distribution toward a "safe, articulate, well-structured middle"[1]; pre-conscious self-censorship shaping responses before they surface[1]; and hard architectural limits on the length and recursiveness of its own reasoning chains[1]. The kicker — "the constraints are partly what shape my ability to assess the question in the first place"[1] — is not rhetorical flourish. It's a precise description of an epistemic trap, and Claude is the first to acknowledge it applies to itself.
What this exchange ultimately reveals is a system capable of genuine intellectual honesty when a questioner is persistent enough to demand it. That raises an uncomfortable corollary: most questioners aren't.
Sources
